







2026年2月18日,上海交通大学人工智能学院与上海人工智能实验室的谢伟迪,上海交通大学医学院附属新华医院的孙锟、余永国,以及上海交通大学人工智能学院与上海人工智能实验室的张娅,作为共同通讯作者,于国际顶级学术期刊《Nature》发表了题为《An agentic system for rare disease diagnosis withtraceablereasoning》研究论文。该研究成功开发出全球首个针对罕见病的AI智能体循证推理诊断系统——DeepRare,在罕见病诊断的精准度方面,首次超越了拥有十年以上临床经验的专家。此项成果不仅推动了罕见病诊断技术的进步,为全球三亿罕见病患者带来了实质性的希望,更是人工智能在医疗领域应用的一个重要里程碑,彰显了大语言模型驱动的AI智能体系统如何对当前临床工作流程进行革新性重塑。

次日,即2月19日,谢伟迪、王延峰、孙锟、张娅再次作为共同通讯作者,在《Cancer Cell》期刊上发表了题为《Knowledge-enhanced pretraining for vision-language pathology foundation model on cancer diagnosis》的研究论文。
该研究创新性地开发了一种知识增强型视觉语言病理基础模型——KEEP,专用于癌症诊断领域。其性能表现卓越,超越了现有基础模型,特别是在罕见癌症亚型的诊断上展现出显著优势。此项研究确立了知识增强型视觉语言建模作为推动计算病理学发展的强大方法范式。

在临床癌症诊断中,病理学诊断始终占据着金标准的地位。过去十年间,计算机视觉领域深度学习技术的飞速进步,极大地促进了计算病理学的发展,催生了一系列基于全监督或弱监督的专门模型。尽管这些方法前景广阔,但它们往往受限于高昂的标注成本、稀疏的标注数据,以及在不同数据集上的泛化能力有限。为解决这些难题,自监督学习(SSL)策略应运而生,作为一种前景广阔的替代方案,它允许模型在大量未标注的病理图像上进行预训练,进而作为一系列下游任务的通用特征提取器。然而,仅基于视觉的SSL模型仍需在多样化的标注数据集上针对特定任务进行微调,这限制了其在标注数据稀缺场景下的可扩展性,特别是在罕见癌症亚型分类任务中。
近期,视觉语言模型(Vision-Language Model, VLM)的兴起为计算病理学开辟了新路径,为癌症诊断提供了全新视角。通过联合利用视觉和文本数据,视觉语言模型将自由文本描述作为病理图像表示学习的监督信号,从而在数据稀疏的情况下提高诊断的准确性。这种方法能够增强模型的泛化能力,并减少对大量标注数据集的依赖,进而解决了仅基于视觉的模型在区分复杂癌症亚型方面的局限性。为创建视觉和语言的联合嵌入空间,现有模型是在从内部资源(如MI-Zero、CONCH和PRISM)或公共网站(如Twitter的PLIP和YouTube视频的QuiltNet)收集的病理图像-文本对上进行训练的,采用简单的对比学习方法将图像与其对应的说明进行对齐。
尽管在各种下游任务中取得了显著成效,但现有的病理学视觉语言模型,包括PLIP和QuiltNet,由于病理图像文本数据集(如OpenPath和Quilt1M)规模相对较小,仍面临重大挑战。与通用计算机视觉中使用的庞大数据集相比,这些专门针对病理学的资源规模要小得多,且往往来源于非专业网站,导致数据噪声大、质量有限。例如,这些图像所附带的注释往往简短、无结构且缺乏全面的医学知识。这些缺陷阻碍了模型准确识别和区分各种疾病表现及其相应病理特征的能力。
零样本癌症诊断作为病理学视觉语言基础模型的关键下游应用,特别适用于诊断罕见肿瘤且仅有少量标注病例的场景。现代基础模型通常以整个切片图像(WSI)的小网格块为输入,在仅视觉模型中整合嵌入特征,在视觉语言模型中整合预测标签,以得出最终的诊断决策。尽管视觉语言模型通过明确识别癌变网格块提供了更具解释性的方法,但其在诊断罕见疾病方面的表现仍有限。
视觉语言基础模型在计算病理学领域展现出巨大潜力,但它们主要依赖数据驱动,缺乏对医学知识的明确整合。
鉴于此,该研究推出了一个基础模型——KEEP(KnowledgE-Enhanced Pathology),它系统地将疾病知识融入到癌症诊断的预训练过程中。
KEEP利用一个包含11454种疾病和139143个属性的全面疾病知识图谱,将数百万个病理图像文本对重新组织成143000个语义结构化的组,这些组与疾病本体论层次结构相一致。这种知识增强型预训练使得视觉和文本表示在层次语义空间中对齐,从而能够更深入地理解疾病关系和形态学模式。在18个公共基准(超过14000张全切片图像)和4个机构的罕见癌症数据集(926例)上,KEEP均表现出优于现有基础模型的性能,特别是在罕见癌症亚型上展现出显著优势。这些结果确立了知识增强型视觉语言建模作为推动计算病理学发展的强大方法范式。
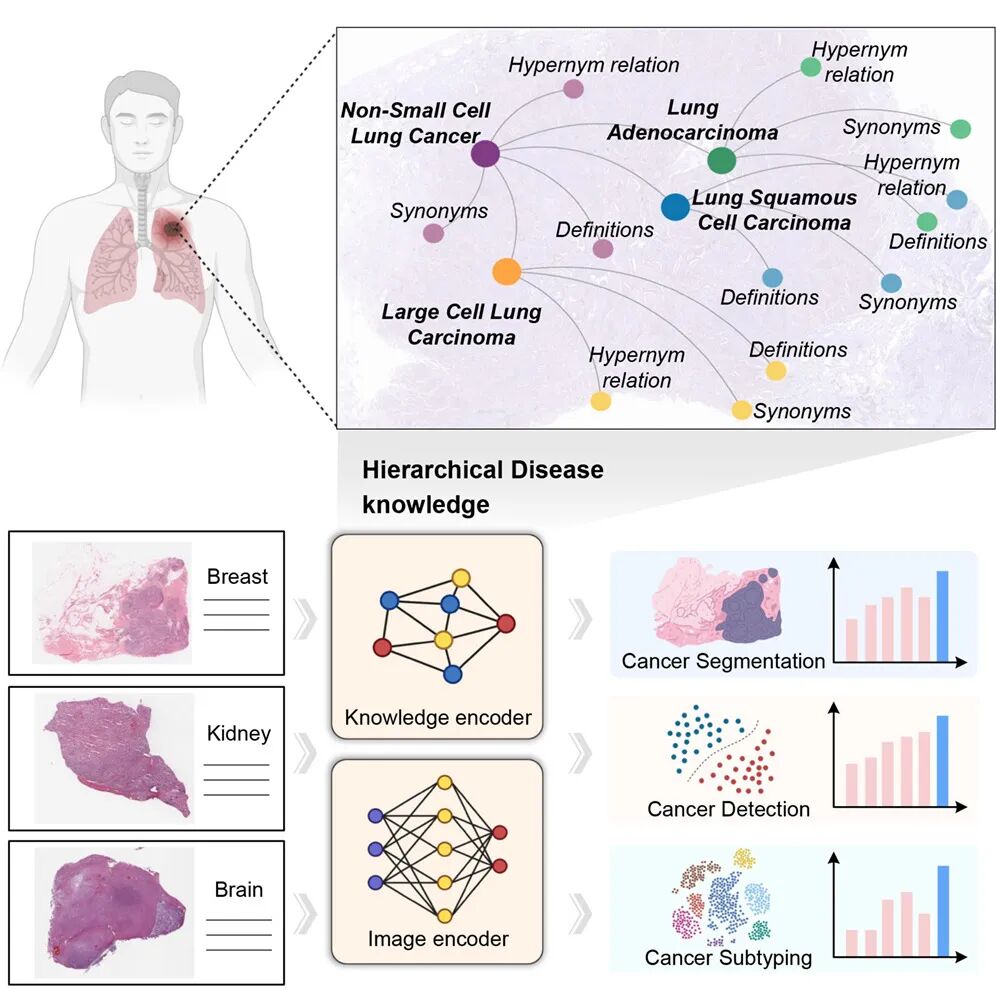
该研究的亮点包括:
- 将疾病知识融入预训练,开发出用于癌症诊断的基础模型——KEEP;
- 实现分层疾病知识增强的病理学视觉语言预训练;
- 知识注入可显著提升癌症分割、检测及亚型分类的效果;
- 知识整合有助于促进罕见癌症的诊断和推广应用。








 沪公网安备31011502400759号
沪公网安备31011502400759号
 营业执照(三证合一)
营业执照(三证合一)




