







在当下科技浪潮中,人工智能(AI)尤其是大语言模型发展势头迅猛。其核心基础在于海量训练数据,这些数据皆源自真实人类创作的文本、视频和图像。人类借助这些数据精心教导AI模型,使其能够精准识别模式并生成相应内容。毫无疑问,人类在AI的训练进程中扮演着至关重要的角色。然而,一个引人深思的问题随之浮现:AI是否也在反向“训练”着我们呢?
近期,越来越多的研究报告揭示出一个令人警醒的现象:人们在使用大语言模型(LLM)的过程中,会不自觉地受其影响,逐渐习得其写作模式、推理方法,甚至在观点形成上也受到潜移默化的作用。
近日,南加州大学的研究团队在Cell子刊《Trends in Cognitive Sciences》上发表了一篇颇具影响力的观点文章,题为《The homogenizing effect of large language models on human expression and thought》(大语言模型对人类表达和思维的同质化影响)。
该文章着重指出,大语言模型(LLM)正悄然成为人类表达和思维走向同质化的“幕后推手”。在其影响下,我们每个人的语言风格、观点倾向,乃至思考问题的方式,都呈现出愈发相似的趋势。更为惊人的是,这种同质化现象的影响范围极为广泛,甚至会波及那些并未直接使用AI的人群。
文章作者之一、南加州大学计算机科学家Zhivar Sourati进一步解释道,倘若你身边的人都在频繁与这些大语言模型互动,并且纷纷采用模型所呈现的表达风格、观点立场以及推理逻辑,那么久而久之,你会发现自己仿佛置身于一个无形的“信息茧房”之中。这种环境会让你产生一种错觉,似乎只有按照这种方式来表述信息,才更符合社会的普遍规范和大众的期待。

当你正为一篇工作报告愁眉不展,或是对一封重要邮件的措辞反复斟酌时,只需打开像ChatGPT、DeepSeek这类基于大语言模型(LLM)的AI工具,输入几个关键信息,短短几秒,一段条理清晰、用词恰当、逻辑连贯的文字便会跃然眼前。你只需稍作调整,便可点击发送,这般高效便捷,着实让人满意。
事实上,这已然成为众多人的日常操作。大语言模型正以前所未有的态势深度融入我们的生活,它不仅是写作时的得力助手,还是创意激发的亲密伙伴,甚至在决策过程中,也如同我们的“外脑”一般,提供着支持与参考。
然而,在我们愈发依赖这些AI助手的同时,是否思考过,它们正以一种不易察觉的方式,悄然改变着我们自身呢?
认知多样性,体现在语言风格、观点视角以及推理策略的差异上,它是人类创造力、集体智慧和适应能力的基石。这种多样性深深扎根于我们不同的文化背景、历史经历以及个体经验之中。
不同的语言风格,宛如一面镜子,能够映射出人的个性、年龄,甚至健康状况。例如,阿尔茨海默病在早期就有着独特的语言特征。不同的观点,则是构建健康公共讨论的基石,让各种声音得以碰撞、交流。而不同的推理方式,比如有的基于生态关系进行归类,有的则依据物种分类法,这使得群体在面对复杂问题时,能够各展所长,找到多样化的解决方案。
但令人惋惜的是,大语言模型的设计与运行机制,却在不知不觉中侵蚀着这种珍贵的多样性。
先看语言的“美颜滤镜”现象。研究显示,当人们借助LLM对各类文本进行“润色”,无论是社交媒体上的帖子、新闻稿,还是学术摘要,甚至是个人随笔,这些文本的写作复杂程度都会趋于一致。原本那些能够预测作者政治倾向、性格、性别或年龄的语言特征,比如特定词汇的使用频率,变得难以分辨。这意味着,经过AI修饰后的文字,虽然更加“规范”“流畅”,却也抹去了个人独特的语言印记。更为严峻的是,这种“语言美颜”还可能掩盖如阿尔茨海默病早期语言特征等重要的健康信号,让我们错过早期发现和干预的机会。
再瞧观点的“主流回声”情况。相关文章指出,LLM所呈现的观点,往往倾向于反映西方、高受教育程度、工业化、富裕社会的特征。当被询问对某些议题的看法时,LLM生成的回答不仅在多样性上远远低于真实人类,而且更贴近所谓的“主流”或“社会认可”的立场。即便我们尝试让AI模拟特定身份,其结果也常常是刻板印象的简单堆砌,而非真实、多元的群体经验。当我们频繁与这些观点高度一致的模型“对话”,我们自身的观点和表达框架,也可能会在不知不觉中被其“校准”,逐渐失去独特的视角和见解。
最后说说思维的“最佳路径”依赖问题。在推理和创造领域,多样性是创新突破的关键因素。然而,LLM通常被训练和优化以追求“最佳性能”,即更高的准确性、有用性和无害性。广泛应用的“思维链”(Chain of Thought,CoT)提示等技术,虽然能够提升逻辑性,但也强化了线性、显式的推理模板。研究表明,在创意构思任务中,借助LLM协助的人虽然能够产出更多、更详细的点子,但不同参与者产出的点子在语义上的相似度也显著升高。更值得关注的是,神经科学研究发现,与独立写作或使用搜索引擎辅助相比,使用LLM辅助写作时,大脑的神经耦合程度最弱,记忆召回能力也更差。这意味着,我们可能正在将思考和创造的核心过程“外包”给AI,并为此付出认知能力退化的代价。
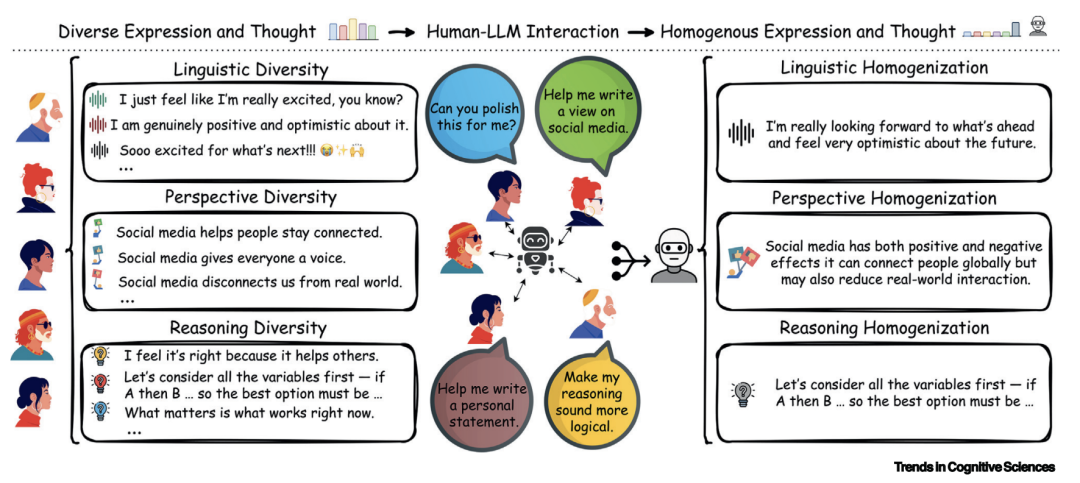
这种同质化现象绝非偶然降临。一方面,LLM所依赖的训练数据,本身就存在过度偏向网络主流语言和观点的问题。那些在网络上占据主导地位的语言风格、观点倾向,在训练数据中占据了极大比例,为同质化埋下了伏笔。另一方面,LLM的训练目标聚焦于预测下一个词,这种特性使得它天然地倾向于学习并复制最常见、最容易广泛应用的模式,而那些少数、特殊的表达方式则会被无情“抹平”。
更为棘手的是循环反馈机制带来的恶性循环。随着越来越多的人选择使用少数几个主流的LLM,大量同质化的内容如潮水般涌入网络。而这些同质化的内容,又摇身一变成为训练下一代模型的数据“养料”。新一代模型基于这些数据输出内容,进一步加剧了同质化程度。这一过程就像一个不断收紧的漩涡,将人类表达原本丰富多彩的多样性,无情地卷入一个愈发狭窄的通道之中。
论文作者将这一现象形象地类比为社会学领域的“麦当劳化”。在追求效率、可预测性和控制的道路上,我们往往以牺牲情境的丰富性和独特性作为代价。在认知领域,我们正逐渐用流畅、一致的AI输出,取代那些基于具体情境、独具特色的思考方式。原本多元的思考视角,在AI的“标准化”输出面前,变得千篇一律。
当然,论文作者并非要对AI的价值全盘否定,而是发出了警惕风险的诚挚呼吁。他们进一步提出了几个极具前瞻性的关键研究方向。例如,如何让AI的“对齐”技术真正做到尊重人类认知的深层多样性,而不是仅仅制造一些表面的差异?长期依赖AI进行思考,会对我们的大脑产生哪些不可逆转的影响?能否通过精心的产品设计,帮助使用者在使用AI的过程中保持主动性和独特性,避免被AI“同化”?
大语言模型(LLM)无疑是一类威力强大的工具,但我们必须清醒地认识到,它绝非只是一个被动的存在。它是一个充满活力、具有强大塑造能力的参与者,正与我们携手共同书写未来思维的“源代码”。在尽情享受AI带来的便利与高效时,我们或许应该时常停下脚步,认真反思:当我们借助AI来表达时,我们是在不断增强自身的表达能力,还是在不知不觉中逐渐遗忘自己独特的声音?当AI能够替我们思考时,我们是在解放大脑,让它有更多精力去探索更深层次的未知,还是在悄无声息中,让所有人的思想都走向一个由数据定义的“标准答案”,失去原本的个性与色彩?
在AI时代,保护人类语言、思维和表达的“生态多样性”,或许将成为人类面临的最重要文化命题之一。这需要开发者在技术研发中秉持多元包容的理念,研究者深入探索潜在影响与应对策略,政策制定者制定科学合理的规范与引导政策,更需要每一位使用者保持清醒的认知和主动的思考。唯有各方共同警醒、携手努力,才能守护好人类认知与表达的独特“生态”。








 沪公网安备31011502400759号
沪公网安备31011502400759号
 营业执照(三证合一)
营业执照(三证合一)




