







引言
结直肠癌(Colorectal Cancer, CRC)作为全球范围内最常见的恶性肿瘤之一,其发病率和死亡率一直居高不下。根据世界卫生组织国际癌症研究机构(IARC)发布的2020年全球癌症统计数据显示,结直肠癌在全球新发癌症病例中排名第三,在癌症相关死亡中排名第二。尽管近年来在早期筛查技术和治疗手段方面取得了显著进展,但结直肠癌的防治仍面临重大挑战,特别是在年轻人群中发病率的上升趋势令人担忧。结直肠癌的高度异质性使得其分子诊断和治疗反应预测变得异常复杂,这促使研究人员不断探索更精确的分子标志物。
随着高通量测序技术的快速发展,癌症基因组图谱(The Cancer Genome Atlas, TCGA)等大型公共数据库积累了海量的癌症多组学数据,为结直肠癌的分子机制研究提供了宝贵资源。与此同时,机器学习技术在生物医学领域的应用日益广泛,为从复杂的高维基因组数据中提取有价值的信息提供了强有力的工具。本文将系统探讨如何整合生物信息学分析与机器学习方法,从TCGA结直肠癌数据中发现潜在的诊断和预后生物标志物。

数据获取与预处理
本研究基于TCGA数据库中结直肠癌(COADREAD)项目收集的695个样本数据,其中包括644个肿瘤样本和51个正常对照样本。这种样本分布呈现出明显的不平衡性(肿瘤:正常≈12.63:1),这在生物医学数据分析中较为常见,但可能导致机器学习模型训练过程中的偏差问题。
数据预处理是确保后续分析可靠性的关键步骤。首先对原始表达谱数据进行标准化处理,常用的方法包括FPKM或TPM标准化,以消除技术变异的影响。随后进行批次效应校正,特别是对于来自不同测序中心或不同时间点的数据,可以采用ComBat或limma等算法进行调整。对于包含大量零值的单细胞RNA-seq数据,还需要考虑专门的零膨胀模型处理。
针对样本不平衡问题,本研究采用了过采样(Oversampling)技术,通过在少数类样本中进行有放回的抽样或合成少数类过采样技术(SMOTE),使两类样本数量达到平衡。这种方法有助于防止机器学习算法过度偏向多数类,提高模型对少数类的识别能力。然而,过采样也可能引入一定的噪声,因此需要在模型评估阶段进行严格的交叉验证。
多维数据探索分析
在正式建模前,对高维基因组数据进行探索性分析至关重要。主成分分析(PCA)和t分布随机邻域嵌入(t-SNE)是两种常用的降维可视化技术。在本数据集中,这两种方法均显示肿瘤样本与正常样本在低维空间中的分布存在明显分离,这从数据层面支持了使用监督学习方法构建分类模型的合理性。
差异表达分析是识别癌症相关基因的传统方法。本研究采用DESeq2或edgeR等专门为RNA-seq数据设计的工具,设置了错误发现率(FDR)<0.05和|log2FC|>1的阈值标准,共鉴定出2933个差异表达基因(DEGs),其中1832个基因上调,1101个基因下调。这些基因富集的通路分析通常揭示与细胞周期、免疫反应、代谢重编程等癌症特征相关的生物学过程。
机器学习特征选择方法
机器学习方法为基因特征选择提供了不同于传统统计学的视角。本研究比较了多种特征选择算法,包括最小绝对收缩和选择算子(LASSO)、随机森林(Random Forest)的特征重要性评分、支持向量机递归特征消除(SVM-RFE)等。其中LASSO回归因其能够同时进行特征选择和正则化的特点,在本研究中表现出色,筛选出61个最具判别力的基因特征。
LASSO(Least Absolute Shrinkage and Selection Operator)回归通过在损失函数中加入L1正则化项,可以将不重要变量的系数压缩为零,从而实现特征选择。其优化目标函数为:
min(1/2n)||y-Xβ||²₂ + λ||β||₁
其中n为样本数,y为响应变量,X为设计矩阵,β为回归系数,λ为正则化参数。通过交叉验证选择最优的λ值,可以平衡模型的拟合优度和复杂度。
值得注意的是,不同特征选择方法的结果往往只有部分重叠,这反映了各种算法捕捉基因表达模式的不同视角。将机器学习筛选的特征与传统差异表达基因取交集,可以提高所发现标志物的可靠性。在本研究中,两种方法的交集包含38个基因,进一步通过生存分析和独立数据集验证,最终确定了5个最具潜力的候选基因:VSTM2A、ETFDH、GLDN、NR5A2和TMEM236。
候选基因的生物学意义与临床价值
对最终筛选出的5个关键基因进行深入分析,可以揭示其在结直肠癌发生发展中的潜在作用:
VSTM2A(V-set and transmembrane domain containing 2A)是一种跨膜蛋白,已有研究表明其在免疫调节中可能发挥作用。本研究发现在结直肠癌组织中VSTM2A表达显著下调(p=0.014),且与患者预后相关,提示其可能作为抑癌基因发挥作用。
ETFDH(Electron Transfer Flavoprotein Dehydrogenase)是线粒体电子传递链中的重要组分,参与脂肪酸β氧化和氨基酸代谢。其表达异常(p=0.047)反映了结直肠癌细胞中代谢重编程的特征,可能与肿瘤微环境酸化及能量供应改变有关。
GLDN(Gliomedin)是细胞外基质蛋白家族成员,在细胞粘附和信号转导中发挥作用。本研究发现其表达水平与结直肠癌进展显著相关(p=0.012),可能影响肿瘤的侵袭和转移能力。
NR5A2(Nuclear Receptor Subfamily 5 Group A Member 2)是一种核受体转录因子,调控胆汁酸代谢和肠道稳态。其表达改变(p=0.029)可能通过影响Wnt/β-catenin等关键信号通路参与结直肠癌发生。
TMEM236(Transmembrane Protein 236)的功能研究较少,本研究发现其表达与结直肠癌显著相关(p=0.043)。通过蛋白质互作网络分析,发现TMEM236可能与多个膜运输蛋白相互作用,暗示其在细胞信号转导中的潜在作用。
这些基因不仅在表达水平上显示出诊断价值,其组合模式也可能为结直肠癌的分子分型提供新线索。通过Kaplan-Meier生存分析评估这些基因的预后价值,并利用GEPIA等在线工具在独立队列中进行验证,可以增强研究结论的可信度。
整合分析的挑战与优化策略
尽管机器学习与生物信息学的整合应用展现出巨大潜力,但在实际研究中仍面临诸多挑战:
数据异质性:TCGA等公共数据库中的样本来自不同中心,使用不同平台和protocol采集,即使经过批次校正,残留的技术变异仍可能影响分析结果。采用谐波分析(Harmonization)或深度学习中的域适应(Domain Adaptation)技术可能提供更好的解决方案。
特征稳定性:高维基因组数据中,不同特征选择方法的结果往往不一致。采用集成特征选择(Ensemble Feature Selection)策略,结合多种算法的共识结果,可能提高发现真实信号的几率。同时,使用bootstrap重采样评估特征选择的稳定性也很有必要。
模型可解释性:尽管深度学习等复杂模型可能获得更高的预测准确率,但其"黑箱"特性限制了在生物医学领域的应用。近年来发展的可解释AI技术,如SHAP值分析、LIME方法等,有助于揭示模型的决策基础,增强研究发现的可信度。
临床转化障碍:从生物标志物发现到临床应用存在巨大鸿沟。理想的转化路径应包括:独立队列验证、实验功能验证、检测方法标准化、临床实用性评估等环节。建立多学科合作团队对于推动机器学习发现的临床转化至关重要。
未来发展方向
随着单细胞测序、空间转录组等新技术的普及,结直肠癌研究正进入更精细的分子层面。机器学习方法在这些新兴领域的应用前景广阔:
单细胞多组学整合:通过图神经网络(GNN)等方法整合单细胞转录组、表观组和蛋白组数据,可以在更高分辨率下解析结直肠癌的肿瘤异质性和微环境特征。
时空动态建模:结合患者纵向样本和空间转录组数据,使用递归神经网络(RNN)或Transformer架构建模结直肠癌的进化轨迹和空间异质性。
药物反应预测:整合癌细胞系筛选数据、患者类器官模型和临床用药记录,构建深度学习模型预测个体化治疗方案。
多模态数据融合:将基因组数据与病理图像、放射组学特征和临床指标相结合,开发更全面的结直肠癌诊断和预后评估系统。
结论
机器学习与生物信息学的协同应用为结直肠癌生物标志物发现提供了强大工具。本研究展示的整合分析框架,通过结合差异表达分析和多种机器学习特征选择方法,能够从高维基因组数据中识别出可靠的候选标志物。未来随着算法创新和数据积累,这种多学科交叉方法有望为结直肠癌的精准诊断和治疗带来新的突破。然而,需要注意的是,计算发现的生物标志物必须经过严格的实验验证和临床评估才能真正转化为临床应用。
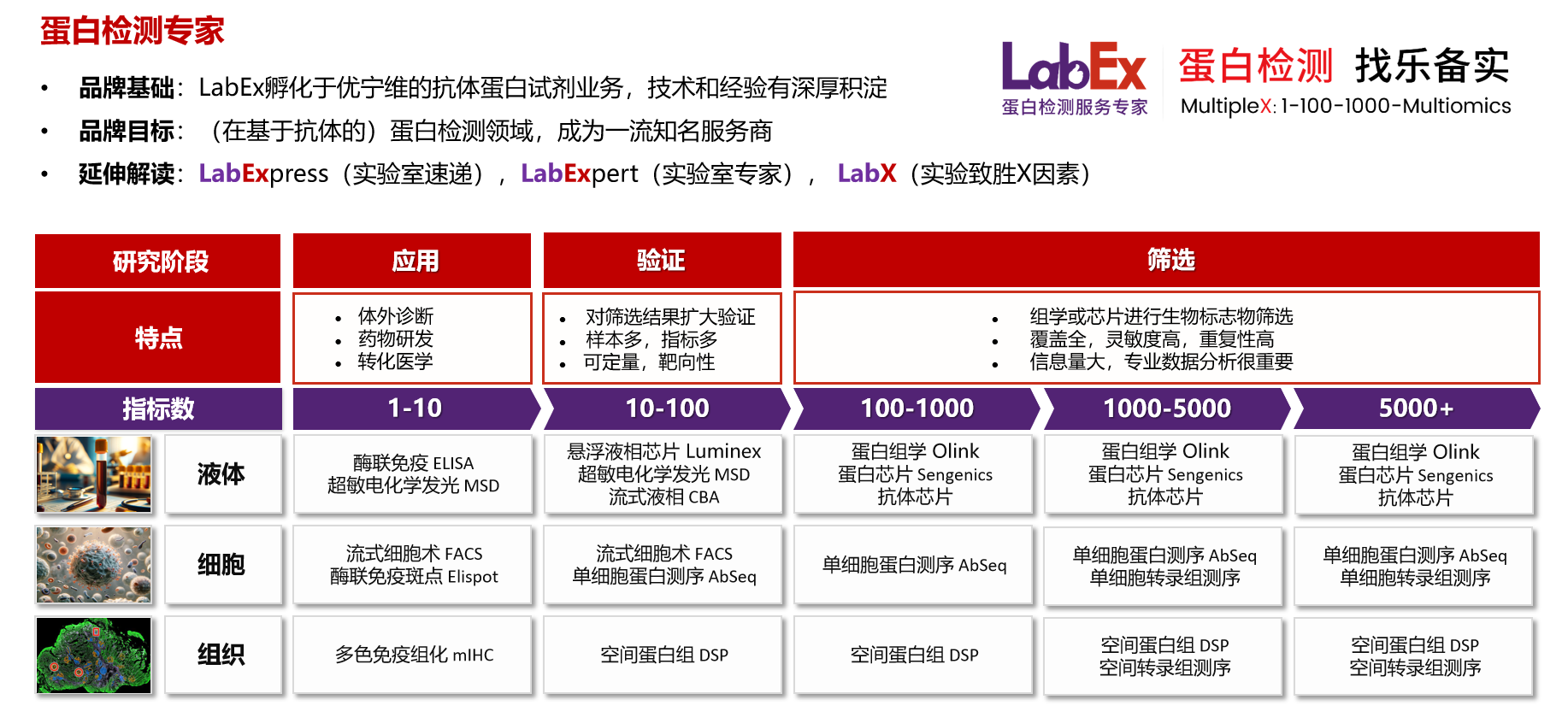
乐备实是国内专注于提供高质量蛋白检测以及组学分析服务的实验服务专家,自2018年成立以来,乐备实不断寻求突破,公司的服务技术平台已扩展到单细胞测序、空间多组学、流式检测、超敏电化学发光、Luminex多因子检测、抗体芯片、PCR Array、ELISA、Elispot、多色免疫组化等30多个,建立起了一套涵盖基因、蛋白、细胞以及组织水平实验的完整检测体系。
我们可提供从样本运输、储存管理、样本制备、样本检测到检测数据分析的全流程服务。凭借严格的实验室管理流程、标准化实验室操作、原始数据储存体系以及实验项目管理系统,已经为超过3000家客户单位提供服务,年检测样本超过100万,受到了广大客户的信任与支持。







 沪公网安备31011502400759号
沪公网安备31011502400759号
 营业执照(三证合一)
营业执照(三证合一)




