







说起功能富集分析,科研人大多都用过,但真要精准说清它的定义,能立刻答上来的可不多 —— 组会时,你是不是也常被导师这样突然 “灵魂拷问” 呀~

大多科研人对功能富集分析的初印象,都源于测序公司交付的分析结果 —— 但如果对概念只是一知半解,不仅会导致数据解读不透彻,更难让测序数据真正转化为有价值的科研结论。
功能富集分析到底是什么?GO 和 KEGG 又该如何理解?怎样做才能得到最准确的分析结果?今天,我们就围绕这几个核心问题,从起源、定义到实例操作,带大家彻底搞懂功能富集分析。
01 何为功能富集分析?
简单来说,功能富集分析就是将杂乱的基因 / 蛋白列表,按功能进行分类聚类的分析方法。具体而言,它会把列表中具有相似生物学功能的基因 / 蛋白归为一类,并进一步关联到具体的生物学表型,让原本零散的基因 / 蛋白数据呈现出明确的功能指向性。
02 何为 GO 和 KEGG?
为了规范基因功能分类、解决 “基因功能如何标准化描述” 的问题,科学家们构建了多个权威基因功能注释数据库 —— 其中,Gene Ontology(基因本体论,简称 GO)和 Kyoto Encyclopedia of Genes and Genomes(京都基因与基因组百科全书,简称 KEGG)是科研中最常用的两大工具。
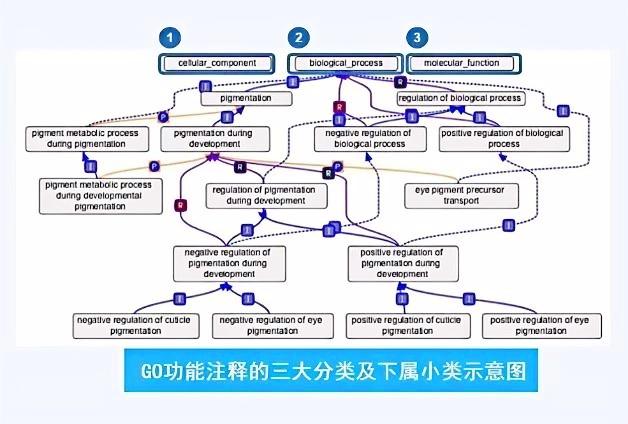
先说说GO 数据库:它是由基因本体论联合会打造的 “基因功能通用词典”,核心作用是为不同物种的基因 / 蛋白提供统一、可更新的功能描述标准。GO 的注释体系分为三大类,能从不同维度完整定义基因功能:
- 分子功能(MF):基因 / 蛋白的具体分子活性(如酶活性、结合活性);
- 生物学过程(BP):基因参与的一系列连续生物学事件(如细胞增殖、炎症反应);
- 细胞组分(CC):基因 / 蛋白在细胞内的定位(如细胞膜、细胞核、核糖体)。
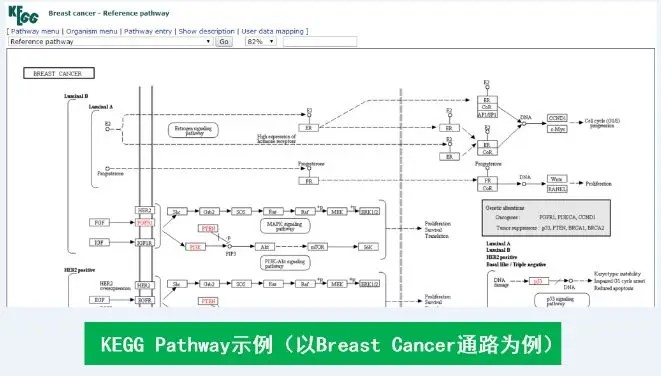
再看KEGG 数据库:很多人会误以为它只是个 “通路数据库”,其实这只是它的 “核心技能” 之一!KEGG 是一个整合了基因组、化学物质、生物系统功能的综合性数据库,包含 4 个大类、17 个子数据库。其中,KEGG Pathway 子数据库因专门收录不同物种的基因通路信息(也是科研中最常用的模块),才让 “KEGG = 通路分析” 的印象深入人心。
下面我们结合具体实例,带大家看看 GO 三大分类和 KEGG Pathway 在数据库中的原始呈现形式:
03 如何做功能富集分析?
功能富集分析的算法和工具种类繁多,涵盖在线工具、本地软件等不同类型。如果想深入探索各类工具的使用方法,以下整理了常用工具列表,供大家参考学习:
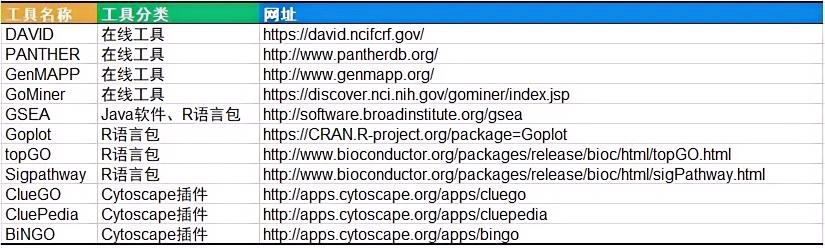
在众多功能富集分析工具中,DAVID 无疑是最常用且权威的核心选择!官网地址为:https://david.ncifcrf.gov/。
之所以说 DAVID 权威性拉满,数据就是最好的证明:仅工具本身就已发表 10 篇 SCI 论文,其中 5 分以上高影响力文章达 7 篇,累计影响因子近 85 分;而科研界利用 DAVID 完成分析并发表的相关研究成果,更是不计其数,是经得起学术检验的 “老牌靠谱工具”~









 沪公网安备31011502400759号
沪公网安备31011502400759号
 营业执照(三证合一)
营业执照(三证合一)




